




声明:本网站所有内容均为资源介绍学习参考,如有侵权请联系后删除
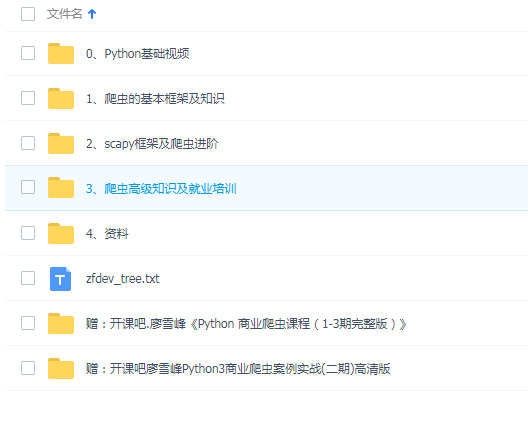

0.Python基础视频
1.爬虫的基本框架及知识
2.scapy框架及爬虫进阶
3、爬虫高级知识及就业培训
4.资料
zfdev_tree.txt
赠:开课吧廖雪峰《Python 商业爬虫课程(1-3期完整版)》
赠:开课吧廖雪峰Python3商业爬虫案例实战(二期)高清版
【课程大纲】
网络爬虫
简介
.爬虫的价值
.爬虫的合法性问题
.通用爬虫与聚焦爬虫
HTTP与HTTPS
.HTTP原理
.HTTP和HTTPS
.HTTP请求过程
.get和post请求
.常用请求报头
.响应
网页的组成
与结构
.HTML与HTML5
.CSS&CSS3
.Javascript
掌握Xpath
.什么是XPath?
.XPath 开发工具
.XPath语法交互环境
requests的使用
.requests的get请求
.requests的post请求
.编码格式
.requests高级操作-文件上传
.requests高级操作-获取cookie
.requests高级操作-证书验证
.案例1:《抓取CoinDesk新闻》
urllib的使用
.urllib的基本使用
.urllib的get请求
.urllib的post请求
.Handler处理器和自定义Opener
.URLError与HTTPError
.案例2:《抓取网易公开课视频》
BeautifulSoup
的使用
.BeautifulSoup介绍
.基本用法
.节点选择器
.方法选择器
.CSS选择器
.案例3:《抓取allitebooks网站所有电子书》
正则表达式
.什么是正则表达式
.正则表达式匹配规则
.re 模块的使用
.match、search、sub、compile方法
.group分组
.案例4:《时间格式化》
使用代理
.代理种类:HTTP、HTTPS、SOCKS5
.抓取免费代理
.使用付费代理
.urllib和requests使用代理
.案例5:《自建代理池》
数据存储
.txt、json、csv文件存储
.MySQL数据库的使用
.NoSql是什么
.MongoDB简介
.MongoDB的使用
.Redis数据库的使用
Scrapy的简介
.安装Scrapy
.Scrapy架构
.Scrapy的数据流
.Scrapy Shell的使用
.Spider类的使用
Scrapy选择器
.css选择器与Scrapy选择器对比
.使用选择器
快速创建
Scrapy爬虫
.新建项目
.明确目标 (编写items.py)
.制作爬虫 (spiders/xxspider.py)
.存储内容 (pipelines.py)
下载器与爬虫
中间件的使用
.反爬虫机制与策略
.突破反爬虫策略
.设置下载中间件
.DOWNLOADER_MIDDLEWARES 设置
使用管道
Pipelines
.管道的介绍
.管道的设置
.管道的使用
.案例6:《抓取麦田租房信息》
Selenium与
PhantomJSbr
的使用
.Selenium与PhantomJS的介绍和安装
.Selenium 库里的WebDriver
.页面操作
.鼠标动作链
.填充表单
.弹窗处理
.页面切换
Headless Chrome 与Headless FireFox
.Headless Chrome 与 Headless FireFox
的详细介绍
.Headless Chrome 与 Headless FireFox
对浏览器版本的支持
.Headless模式运行selenium
.案例7:《抓取微信公众号》
使用Splash
.Splash介绍
.Splash的安装
.Splash与Scrapy结合
.使用Splash执行Javascript
Ajax数据抓取
.Ajax的工作原理
.Ajax的分析方法
.json数据的分析
.提取json数据的有用信息
Scrapy-Redis
源码分析及实现
.Scrapy 和 scrapy-redis的区别
.分布式技术原理
.connection、Dupefiler、PicklecompatPipelines、Queue、Scheduler源码分析
.增量式抓取与布隆过滤器
.案例8:《分布式抓取麦田二手房信息》
Python
实现模拟登陆
.分析登录过程(豆瓣、果壳、京东等)
.案例9:《模拟登录微博》
cookies池使用
.cookies池架构设计
.cookies池架构实现
破解常见验证码
(OCR工具、
打码工具)
.使用tesserocr
.点触验证码
.geetest验证码
App数据抓取
.使用fiddler、charles、wireshark、mitmproxy
.案例10:《抓取得到电子书信息》
.Appium的使用
.案例11:《抓取拼多多商品信息》
抓包工具
.使用fiddler、charles、wireshark、mitmproxy
抓包过程分析
.案例10:《抓取得到电子书信息》
Appium
.Appium的使用
Appium与mitmproxy
结合使用
.案例11:《抓取拼多多商品信息》
基于Scrapy框架的北京房产信息多平台抓取实现
基于Docker的分布式抓取平台的设计与实现